Use Case
Deliver Successful AI Agents
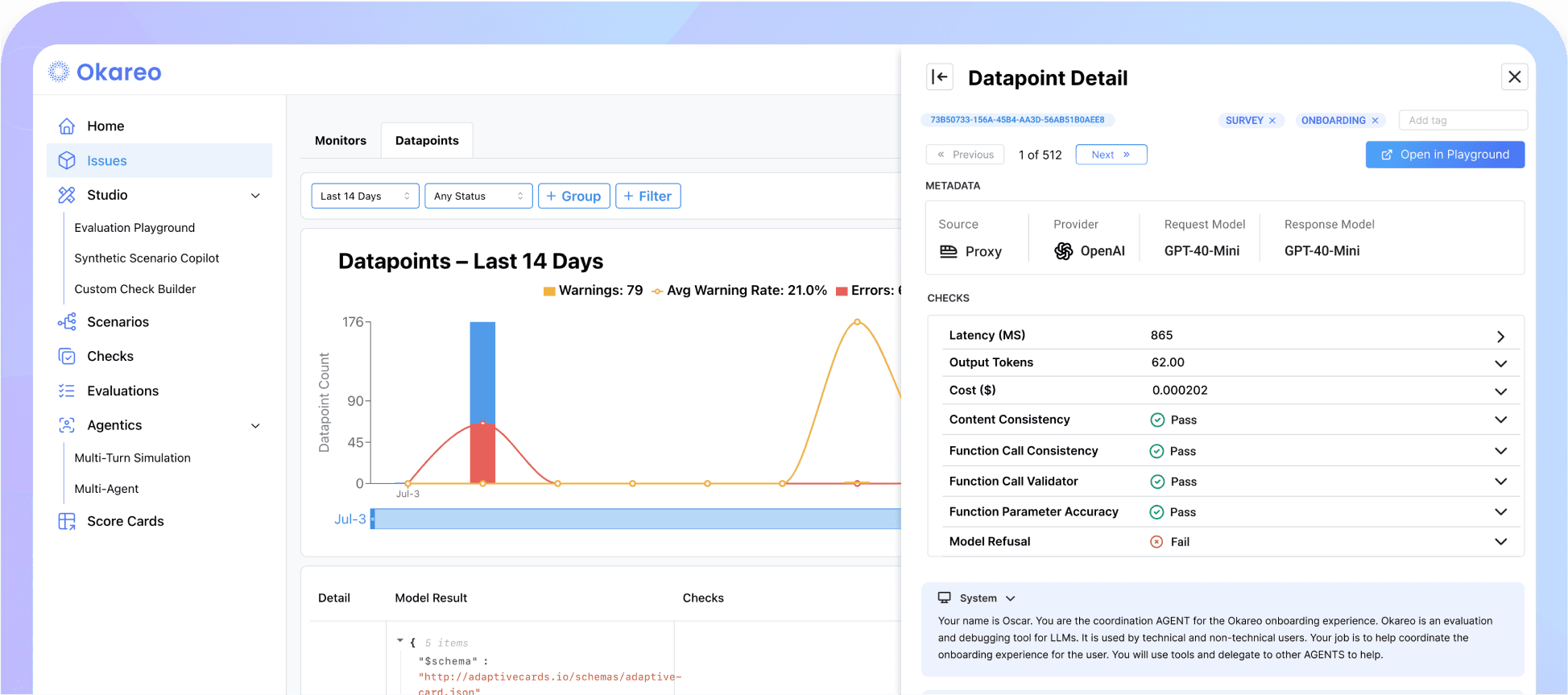
Debug, evaluate, monitor, and fine-tune AI Agents for peak performance

Supports Your Agent Use Case
Autonomous agents that hold conversations and call services require unique approaches to development and evaluation.